The Graphic-Analytical Method
The investigation of prehistoric ethnogenic processes required the analysis of large volume of lexical data selected from various dictionaries. It is not necessary to have perfect command of all these analysed languages when working with dictionaries of different language families, but it is indispensable to know their phonetic peculiarities and rules of their changes according to the requirements of comparative-historical linguistics (MEILLET A, 1938; MEILLET A., 1954; FORTUNATOV F.F.,1956; GAMKRELIDZE T.V., IVANOV V.V., 1984). The work of H. Krahe (KRAHE HANS, 1966) was used while selecting and systematizing of words of the Indo-European languages. The phonetic rules of the Finno-Ugric languages were drawn from the book of Russian linguists Lytkin V.I. and Gulajev E.S. (LYTKIN V. I., GULAYEV E.S., 1970). and the phonetic rules of the Turkic languages were drawn from Baskakov’s classification (BASKAKOV N.A., 1960).
The analysis was performed on the lexical level with the comparison of lexical units within two aspects – phonetic and semantic, h.e. after their appearance and meaning. The phonetic congruencies without semantic conformities were excluded from the study. The evaluation of semantic accordance was performed from synonymy, with more or less semantic similarity, till antonymy, which sometimes can be the consequence of concept characteristics (classical example – initial meaning of the word “side” can be changed to “beginning” and “end”).
The Nostratic, Indo-European, Finno-Ugric, Turkic, Iranian, Germanic, Slavic, Mongolic, Manchu-Tungus languages were studied with this new graphic-analytical method. Two types of table-dictionaries were used for each group of languages. At the beginning, the first type table-dictionary for the language group was compiled, where the semantic list was placed in the far left column but all available synonyms of each semantic concept were placed in forthcoming columns for each analysed language. Then the obtained synonymic nests were analysed for phonetic similarity and it allowed us to select the phono-semantic terms; the other words were added to the list after the analysis of synonyms with similar sense. The selected phono-semantic terms constituted the table-dictionary of the second type where the identifiers of phono-semantic terms were placed in the far left column and available matches from particular languages were placed in the remaining columns. They form phono-semantic set.
The data of these tables provided us with the means to calculate the number of mutual words in the language pairs, necessary for the construction of graphic models for the language relationships within the same language families. These graphic models are the graphs of specific sort, possibly yet to be described (the author has not yet found it in anywhere) in mathematics. This graph can be characterized as a “weighed graph” where not only single nodes but all of them without exclusion form mutual connections and not only the connection itself is important, the distance between all the nodes has to be considered. In this case, each node of graph is not just a point but the aggregate of points and every aggregate correspond to a particular language in the relationship model. Each point of the aggregate is the end of the segment with the length inversely proportional to the number of mutual words in the pair of languages that correspond to those two aggregates connected by this very segment. When the number of mutual words in the language pairs is known, it is possible to determine the set of segments needed to build the graphic model. Even this possibility of the graph construction proves the existence of a certain system in the database but certain doubts may arise. Let’s calculate this probability.
If we take the graph A, which has n mutually connected nodes, each node has (n-1) ribs. As we know from mathematics, it is enough to have only two co-ordinates in any frame of co-ordinates to place a point on a plane. For our graph, we can determine much more pairs of co-ordinates combining all ribs by two with each other. (When the length of ribs is known!). The number of pairs C can be calculated with this known equation:
The Nostratic, Indo-European, Finno-Ugric, Turkic, Iranian, Germanic, Slavic, Mongolic, Manchu-Tungus languages were studied with this new graphic-analytical method. Two types of table-dictionaries were used for each group of languages. At the beginning, the first type table-dictionary for the language group was compiled, where the semantic list was placed in the far left column but all available synonyms of each semantic concept were placed in forthcoming columns for each analysed language. Then the obtained synonymic nests were analysed for phonetic similarity and it allowed us to select the phono-semantic terms; the other words were added to the list after the analysis of synonyms with similar sense. The selected phono-semantic terms constituted the table-dictionary of the second type where the identifiers of phono-semantic terms were placed in the far left column and available matches from particular languages were placed in the remaining columns. They form phono-semantic set.
The data of these tables provided us with the means to calculate the number of mutual words in the language pairs, necessary for the construction of graphic models for the language relationships within the same language families. These graphic models are the graphs of specific sort, possibly yet to be described (the author has not yet found it in anywhere) in mathematics. This graph can be characterized as a “weighed graph” where not only single nodes but all of them without exclusion form mutual connections and not only the connection itself is important, the distance between all the nodes has to be considered. In this case, each node of graph is not just a point but the aggregate of points and every aggregate correspond to a particular language in the relationship model. Each point of the aggregate is the end of the segment with the length inversely proportional to the number of mutual words in the pair of languages that correspond to those two aggregates connected by this very segment. When the number of mutual words in the language pairs is known, it is possible to determine the set of segments needed to build the graphic model. Even this possibility of the graph construction proves the existence of a certain system in the database but certain doubts may arise. Let’s calculate this probability.
If we take the graph A, which has n mutually connected nodes, each node has (n-1) ribs. As we know from mathematics, it is enough to have only two co-ordinates in any frame of co-ordinates to place a point on a plane. For our graph, we can determine much more pairs of co-ordinates combining all ribs by two with each other. (When the length of ribs is known!). The number of pairs C can be calculated with this known equation:
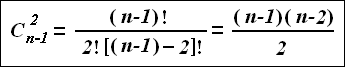
For example, if we have the number of nodes n = 6, the number of pairs C of co-ordinates will be 10, but when n = 10, C increases to 36, and C = 55 when n = 12. Thus if n is as much as 6, we can determine a place for each node in tens different ways. In our case with the graph A when we use all possible variants of nodes arrangement with the ribs of known length, every time some nodes will get to the same point. But when we analyse a real situation, e.g. , the system of cognate languages, the graph B, where each of its nodes is not just a single point but the aggregate of points, which fill small areas and these areas do not overlap each other, can meet our requirements. If we have the number of analysed objects n = 6 and they fill the area S = 1, each object fills the area as big as s =1/6. In that case, the probability for at least one point to get on its own place is equal to 1/6. If we have 6 objects, we can place each node in ten different ways (look above), so the probability for the point to get on the same very place in each of ten cases will be equal to 1/610 = 1: 604 660 176. As far as we have 6 objects, this number has to be multiplied by six times again and we shall obtain a number with 80 zeros in the denominator. If we have ten objects, the number of zeros in the denominator will increase up to 3600. It demonstrates that accidental construction of the graphical model is practically impossible.
The process of building schemes kinship lexical and statistical data will be considered more detail at a specific example of Nostratic languages in the next chapter. The graphic-analytical method can find application not only in linguistics, but also in other science branches where correlation between the large number of common characteristics of different objects and distances between objects in the space (optionally even in two-dimensional) is present. This method has been tested, for example, by statistical data of Fedorov-Davydov (FEDOROV-DAVYDOV, G.A, 1987) who considered a number of common features of ornamental compositions of Central Asian ceramics produced several artists who lived in different parts of Panjakent. As the artistic interaction masters was the stronger the closer they lived together, it became possible to determine the location of their shops in the city. Of course, these data can not be checked, as it is unknown where the master lived in reality, but the possibility of building is already a testament to the effectiveness of a particular method.
It is necessary to emphasize that graphical-analytical method is effective only in the processing of the absolute values or related to a single common one. The assignment of the common features between two objects to their total amount in these languages or one of them can not sufficiently describe these two objects, since the total number of features of any object depends on the location of other objects. Marginal items have a lower number of common features being characterized for this association, and already this characterizes their peripheral position. When we take this reduced value for the denominator, it artificially increases the ratio. This does not imply that marginal objects have less features. They can have them even more, but part of them may belong not to the studied association but the next one.
It is necessary to emphasize that graphical-analytical method is effective only in the processing of the absolute values or related to a single common one. The assignment of the common features between two objects to their total amount in these languages or one of them can not sufficiently describe these two objects, since the total number of features of any object depends on the location of other objects. Marginal items have a lower number of common features being characterized for this association, and already this characterizes their peripheral position. When we take this reduced value for the denominator, it artificially increases the ratio. This does not imply that marginal objects have less features. They can have them even more, but part of them may belong not to the studied association but the next one.