The Settlement of the Indo-European, Turkic, and Finno-Ugric tribes in Eastern Europe.
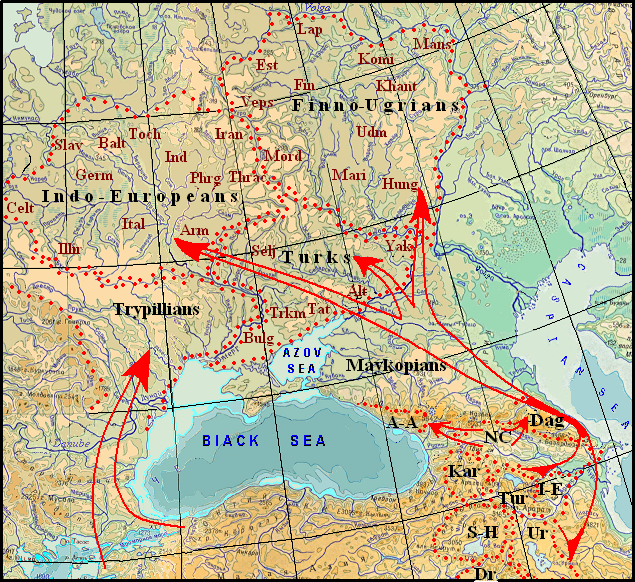
Indo-European, Altaic, and Uralian tribes were among the communities of farmers advanced northward looking for new settlement places. They left their Urheimat in the 6th mill. BC and gradually reached Eastern Europe. The Indo-Europeans were moving as the first, as they had an extreme position in the home land, the Uralians and Altains moved behind them. However, before further narration, there is a need to make some adjustments. The controversial question of the genetic relationship between Turkic with Mongolic and Tungus-Manchu according to obtained results should be solved negatively, since the formation of the proper proto-languages took place in different locations. If Turkic protolanguage was formed together with other Nostratic in Transcaucasia, the formation of Mongolic and Tungus occurred in the Far East in the Amur River basin along with Korean and Japanese parent languages. In addition, the relationship of the Turkic and Mongolian languages is contradicted by the lack of conclusive word matching which may be the most ancient. For example, the numerals of the Turkic and Mongolian languages have no slightest trace of similarity. Meanwhile, this layer of vocabulary was to be one of the oldest and this is confirmed by the Indo-European and Finno-Ugric languages in which the common origin of numerals can be seen quite clearly.
Thus, the similarities between the Turkic and Mongolian languages have to be explained by the later prolonged contacts, obviously, the same is true for the Tungus-Manchurian languages. Such statement does not give reason to doubt the relevance of Svitych Illich's data, who added to the Altaic language also the facts of the Mongolian and Tungus-Manchurian, as he mainly based on the materials of the Turkic languages. Linguistic facts of the Mongolian and Tungus-Manchurian languages in most cases duplicate Turkic ones. When they have no Turkic matches, they appear random, as their correspondences are scarce in other Nostratic languages . The same applies to the facts of language Samoyed languages in relation to the Finno-Ugric peoples, however, denying their genetic relationship is still no reason, but further study of the Uralic languages would be limited to the Finno-Ugric languages, and the study of their relationship with the Samoyed should be separate theme.
The Indo-European Tribes.
The table-dictionary for the Indo-European languages was based on the etymological dictionary of the Indo-European language (POKORNY. J., 1949-1959 ). These data were supplemented with words from the etymological dictionaries of other Indo-European languages (FRAENKEL E.,1955-1965, FRISK H., 1970, HÜBSCHMANN HEINRICH., 1972, KLUGE FRIEDRICH, 1989, WALDE A., 1965. In total 2615 phono-semantic sets of the Slavic, Celtic, Baltic, Germanic, Italic, Greek, Indic (Indo-Aryan), Iranian, Tocharian A and B, Hittite-Luwian, Albanian, Thracian, Phrygian languages were placed into the table-dictionary. 489 sets were admitted as mutual words. The words with the matches found in seven from eight of the most represented languages (Germanic, Greek, Baltic, Indic, Italic, Slavic, Celtic, Iranian) were considered as the common Indo-European stock. Calculation of the mutual words in the language pairs gave the results that are presented in table 3.
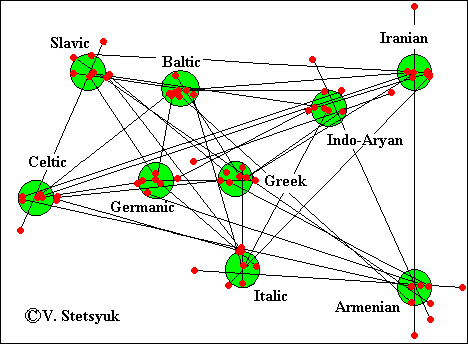
Table 3. Quantity of mutual words in pairs of the Indo-European languages.
Language |
Clav | Celt |
Germ |
Ital |
Greek |
Balt |
Ind |
Iran |
Arm |
Slavic |
732 |
||||||||
Celtic |
307 |
751 |
|||||||
Germanic |
501 |
524 |
1202 |
||||||
Italic |
279 |
368 |
518 |
792 |
|||||
Greek |
371 |
416 |
626 |
493 |
1159 |
||||
Baltic |
530 |
358 |
652 |
359 |
542 | 1015 |
|||
Indo-Aryan |
235 |
275 |
455 |
335 |
511 |
394 |
865 |
||
Iranian |
168 |
195 |
319 |
225 |
346 |
265 |
459 |
616 |
|
Armenian |
151 |
177 |
263 |
222 |
321 |
226 |
232 |
222 |
536 |
Left: Table 3. Quantity of mutual words in pairs of the Indo-European languages.
Right: The model of the Indo-European language relationships was built on the data of the Table 3 by means of
The Graphic-Analytical Method
The Graphic-Analytical Method
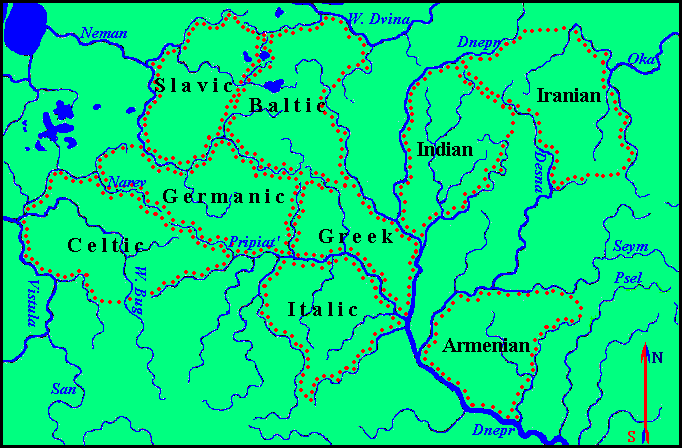
The total number of words for each language is given in the diagonal of the table. The number of mutual words for each pair of languages can be found on the intersection of the corresponding column and line. The data for Tocharian, Hittite-Luwian, Albanian, Thracian, Phrygian are not presented in the table because of the small numbers. The localization of their sites in the relationship model of Indo-European languages is to be analyzed later with the other methods. It should be taken into account that all the data presented here are current and are constantly being corrected while the new terms are found, though these corrections don’t make much influence. The data oscillation of 5-7% does not modify the models at all, the correction results only to the more compact aggregate of points for language sites.
The Indo-European languages are divided into two general branches which are named the Satem and the Centum. The Hittite-Luwian, Italic, Celtic, Germanic, Greek, Tocharian languages belong to the Centum-group. The Slavic, Baltic, Indic, Iranian, Armeinan, and Albanian as the offspring of Thracian languages belong to the Satem-group. Excepting Slavic and Baltic, all Centum-languages are located to the west of the Dniepr and all Satem languages are located to the east of the Dniepr. The transformation of the Indo-European palatal stops k’ , g’, and gh’ into spirants s, s’ or affricates took place under the influence of Finno-Ugric languages which had a great set of spirants. The Dnepr was the effective barrier for these influences if we suppose that this transformation in the Slavic and Baltis languages took place later after the speakers of these languages came in the direct contact with Finno-Ugric languages crossing the Dnepr.
The map of the Indo-European habitats
The Finno-Ugric Tribes.
The vocabulary material for the table-dictionary of the Finno-Ugric languages was mostly taken from bilingual dictionaries according to the semantic list of the basic vocabulary. The list was compiled by the everyday and other most frequent words (names of plants, animals, kinship terms etc.), the same as for the table for Indo-European languages. The etymological dictionary of Komi(LYTKIN V. I., GULAYEV E.S., 1970) provided us with specially interesting data. Such Finno-Ugric languages as Finnish, Estonian, Veps, Komi, Saami, Udmurt (Votyak), Mari (Cheremis), Mordvinic, Khanty (Ostyak), Hungarian and Mansi (Vogul) were taken for analyses. Later Karelian was added to this list, but its vocabulary showed that this language was developed from Finnish. We will not consider this topic in details. The compiled table-dictionary of the Finno-Ugric languages has 1869 isoglosses and 144 of them belong to the common language heritage. (As the common words were considered that found at least in ten from eleven Finno-Ugric languages whout Karelian). Calculation results of mutual words are presented in table 4.

Table 4. Quantity of mutual words in pairs of the Finno-Ugric languages.
|
Language |
Finn |
Udm |
Komi |
Est |
Mari |
Veps |
Kanty |
Mord |
Hung |
Mansi |
Karel |
Saami |
Finnish |
900 |
|||||||||||
Udmurt |
313 |
796 |
||||||||||
Komi |
329 |
627 |
760 |
|||||||||
Estonian |
668 |
264 |
267 |
750 |
||||||||
Mari |
310 |
492 |
431 |
254 |
708 |
|||||||
Veps |
563 |
185 |
186 |
488 |
207 |
650 |
||||||
Khanty |
203 |
333 |
347 |
160 |
277 |
114 |
603 |
|||||
Mordvin |
323 |
301 |
268 |
285 |
339 |
258 |
170 |
547 |
||||
Hung |
184 |
345 |
319 |
152 |
303 |
107 |
324 |
179 |
534 |
|||
Mansi |
167 |
271 |
283 |
129 |
213 |
90 |
413 |
130 |
257 |
507 |
||
Karel |
479 |
121 |
128 |
400 |
131 |
405 |
71 |
166 |
77 |
58 |
492 |
|
Saami |
330 |
214 |
245 |
274 |
215 |
227 |
160 |
182 |
137 |
144 |
176 |
467 |
The model of relationships for the Finno-Ugric languages was built on these data and is presented. The corresponding territory for this model was found in Eastern Europe between the Volga and Don and in the Oka river's basin, where, according to the traditional opinion, the habitats of Finno-Ugric peoples was once situated, although the Finno-Ugric Urheimat is considered to be near the Urals (see the map on the figure 8).
There are on the territory between the rivers Volga and Don many place names of Finno-Ugric origin and some deal of them on the Ethno-Generating Areas can be explicated by means of the languages which began to form on these areas.
The area of the Veps language is placed between the rivers Oka, Moscow, Ugra, Viaz’ma, and Vazuza. The last two river names can be explained by the means of Veps language: - the Viaz’ma – Veps vez’i “water” and ma “country” or the name Viaz’ma can hide the ethnonym of the Veps (in Russian – Ves’) – the country of Veps; the Vazuza – Veps vez’i “water” and uz “new”.
The area of the Estonian language There is on the north of the area the town of Taldom. Its name can be explained as “the house made of oak” – Est talo “house” and tamm “oak”. The other place names can be explicated so:
the river Lama, – Est lame “flat” suits for the local flat country perfectly; the river Sestra – Est sõstar “currants”; the river Yakhroma – Est jõke “river” and *roma “bad, not beautiful” (Fin ruma). The area of the Mordvinic language is located between the upper current of the rivers Oka and Don. The stay of the Mordvins' ancestors here can be affirmed by the name the little river Mordves. The ethnonyms of the Mordvin and Veps can be hidden in this name. There is in the center of the area the city of Tula which name can be explained as “a wedge” (Mord tula “a wedge”). This hypothesis has to be real, as the town of Klin (Russian klin “a wedge’) is located on the North of Moscow Region. The area of the Finnish language is limited by the river Klaz’ma on the north and the river Oka on the south. Such facts can prove the location here of the Finnish Urheimat: - the river Oka can have the same origin as Fin joki “a river”; the town of Likino-Dulevo is located on the swampy flat country and the both words can reflect the peculiarity of the local landscape: Fin lika “mud” (Mari lükö „quagmire“) and Fin tulva „flood, owerflow“; the river Suvoroshch, the right tributary of the Klaz’ma flows on the swampy country, therefore its name can be composed by Fin suo “swamp” and roska(t) “rubbish, litter”; the village Kochemary in Kasimov District of Riazan’ Region is good explained by Fin marja “a berry” and kataja “juniper” (cf. Mari kocho “bitter”); the settling Tuma in Klepiki District of Riazan’ Region can have the same origin as Fin tumma “oak”; the name of the town of Shatura can be explained by Mari word codra “forest”, maybe the similar word existed or exists (?) in the Finnish language.
the river Lama, – Est lame “flat” suits for the local flat country perfectly; the river Sestra – Est sõstar “currants”; the river Yakhroma – Est jõke “river” and *roma “bad, not beautiful” (Fin ruma). The area of the Mordvinic language is located between the upper current of the rivers Oka and Don. The stay of the Mordvins' ancestors here can be affirmed by the name the little river Mordves. The ethnonyms of the Mordvin and Veps can be hidden in this name. There is in the center of the area the city of Tula which name can be explained as “a wedge” (Mord tula “a wedge”). This hypothesis has to be real, as the town of Klin (Russian klin “a wedge’) is located on the North of Moscow Region. The area of the Finnish language is limited by the river Klaz’ma on the north and the river Oka on the south. Such facts can prove the location here of the Finnish Urheimat: - the river Oka can have the same origin as Fin joki “a river”; the town of Likino-Dulevo is located on the swampy flat country and the both words can reflect the peculiarity of the local landscape: Fin lika “mud” (Mari lükö „quagmire“) and Fin tulva „flood, owerflow“; the river Suvoroshch, the right tributary of the Klaz’ma flows on the swampy country, therefore its name can be composed by Fin suo “swamp” and roska(t) “rubbish, litter”; the village Kochemary in Kasimov District of Riazan’ Region is good explained by Fin marja “a berry” and kataja “juniper” (cf. Mari kocho “bitter”); the settling Tuma in Klepiki District of Riazan’ Region can have the same origin as Fin tumma “oak”; the name of the town of Shatura can be explained by Mari word codra “forest”, maybe the similar word existed or exists (?) in the Finnish language.
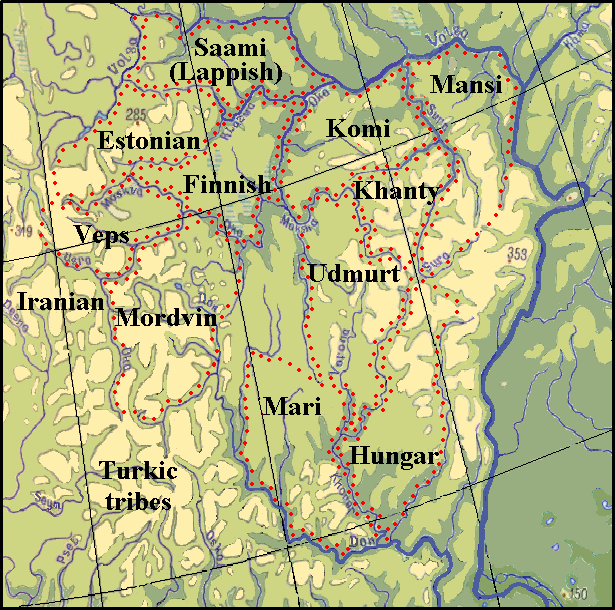
The whole area of the Komi language is located in Nizhniy Novgorod Region. Here some place names can have the Komi origin: Lake Vad and the village Vad – Komi vad “a lake”; Island Barminskiy on the Volga and the town of Barmino – Komi parma “fir forest”; the river Sura, the right tributary of the Volga – Komi shor “a stream” (Udm shur “a river”); the river Tiosha – Komi töshchö “hollow”; the river Seriozha, the right tributary of the Tiosha – Komi ser “pattern” and ezha “sod, turf”; the village of Tamboles in the Vyksun District – Komi tom “young” and pelys’ “mountain ash”. The area of the Mari language is located on the left banks of the Don till the river Khoper, the left tributary of the Don. There is on the north of the area the city of Tambov. Its name can be explained by Mari words tum “oak” and pu “a tree” (Fin puu “a tree”). One can consider also such matches: the river Ertil – Mari er “morning” and tele, tel “winter”; the river Chigla – Mari chigila “sticky”; the river Savala, the right tributary of the Khoper, the left tributary of the Don – Mari savala “a spoon”.
The area of the Udmurt language is placed between the rivers Tsna, Moksha, and Khoper. The name of Region center the city of Penza maybe means “the ashes of grass”: Udm pen’ “ashes” and “zu” (from early za) “stalk”. The name of the center of the district in Penza Region Pachelma can hide three Udmurtian words: puchy “willow”, ul “moist”, and mu (from early ma) “erth”.
The area of the Hungarian language is located between the rivers Khoper and Medeveditsa. Such correspondences are found here: the river Archeda – Hung ár “a current, stream” and sodor “to turn, twirl”; the river Mashka – Hung mészkő “limestone”; the lake Bolshie (Great) Chiganaki – Hung csiga “snail” and nagy “great”; the river Tokay – the Hungarian town of Tokay; two rivers Yelan’ – Hung leany, lany “a girl” and jó “good”. The enigmatic name of the river Khoper can be composed of two Hungarian words hő “warm” and bőr “skin” or bor “wine”.
The complete List of Finno-Ugric Place Names in the Central Russia
The The Turkic Tribes .
While working with the Turkic language family certain difficulties, namely the determination of the analysis objects, occurred. As it is known, this family is large and has as many as thirty members including extinct languages. Some of them are similar in such measure that one can assume their common origin from a language of higher level than parent unitary Turkic. Different classifications of the Turkic languages exist consistent with each other in the recognition of closest relationships. Multi-level historical classifications of the well-known turkologist Baskakov (BASKAKOV N.A., 1960: 37-60) were used for this study. He divided several groups and subgroups of Turkic languages on the highest level. They comprise from one to five-six modern Turkic languages. If we unite close cognate modern languages of separate subgroups in one conventional language, we obtain only thirteen languages that can be considered as self-contained objects for this graphic analysis. Though two extinct tongues as Old-Uighur and Karluk-Uighur could not be analysed because of the absence of necessary dictionaries. According to the genetic connections established by Baskakov, conventional names were used for all Turkic languages taken for the analysis, sometimes identical to the modern names for some languages, but without claim to the historical accuracy and only for the convenience for the further narrative. Thus, the Bulgarish (Volga-Bulgarish) language will be corresponded with the present-day Chuvash and extinct Khazarian languages; Tartaric with the modern Tatar and Bashkir languages; Kypchak with modern Kumyk, Karachai, Balkarian, Crimea-Tatar, and Karaim; Nogai with modern Kazakh, Karakalpakh and properly Nogai; Oghuz with modern Gagauz and the dialects of Balkan Turks; Seljuqic with modern Turkish, Azerbaijani and south dialect of Crimean Tatars; Karlukish with modern Uzbek and New Uighur; Tuba with modern Tuvinian and Karagasian; Khakassian with modern Kamasinian, Shorian, North-Altaic, Sari-Uighur, tongue of Chulim Tatars and properly Khakassian; Altaian with modern South-Altaic. The Kyrghyz, Turkmen, and Yakut languages correspond with proper present-day languages.
The table-dictionary of the Turkic languages was composed of the data taken from etymological dictionaries of Turkic languages (SEVORTYAN E.V. 1974 – 2003; CLAUSON GERARD, Sir., 1972; EGOROV V.G., 1964). The numbers of mutual words in the pairs of languages are given in the table 5.
Table 5. Quantity of mutual words in pairs of the Turkic languages.
Lang |
Nog |
Karl |
Kyrg |
Tart |
Selj |
Kypc |
Khak |
Turk |
Bulg |
Tuba |
Alt |
Oguz |
Yak |
Nogai |
1195 |
3,0 |
3,0 |
3,1 |
3,7 |
3,5 |
4,2 |
3,7 |
5,6 |
6,5 |
5,6 |
7,3 |
7,5 |
Karluk |
948 |
1178 |
3,2 |
3,4 |
3,6 |
3,5 |
4,4 |
3,7 |
5,6 |
6,5 |
5,9 |
7,2 |
7,9 |
Kyrgh |
949 |
882 |
1111 |
3,5 |
4,1 |
3,9 |
4,3 |
4,2 |
6,7 |
6,2 |
5,5 |
8,3 |
7,4 |
Tartar |
921 |
830 |
809 |
1077 |
4,1 |
3,7 |
4,9 |
4,2 |
5,4 |
7,3 |
6,1 |
7,8 |
8,6 |
Seljuk |
752 |
790 |
676 |
676 |
1060 |
3,8 |
4,9 |
3,9 |
6,4 |
7,9 |
7,1 |
5,5 |
9,9 |
Kypch |
810 |
801 |
721 |
759 |
750 |
1020 |
4,7 |
4,2 |
6,2 |
7,9 |
7,1 |
7,1 |
9,0 |
Kakas |
636 |
681 |
650 |
563 |
571 |
591 |
945 |
5,6 |
9,3 |
5,9 |
6,4 |
10,3 |
7,6 |
Turkm |
752 |
755 |
671 |
669 |
724 |
673 |
480 |
936 |
6,7 |
8,6 |
7,5 |
6,7 |
10,5 |
Bulg |
484 |
453 |
405 |
523 |
428 |
432 |
273 |
401 |
668 |
13,7 |
10,7 |
10,7 |
16,2 |
Tuba |
414 |
412 |
429 |
359 |
327 |
341 |
461 |
297 |
169 |
629 |
8,5 |
16,7 |
7,9 |
Altai |
488 |
463 |
494 |
442 |
373 |
376 |
418 |
346 |
231 |
313 |
598 |
14,7 |
10,7 |
Oghuz |
363 |
366 |
312 |
335 |
493 |
378 |
239 |
403 |
231 |
130 |
155 |
541 |
20,0 |
Yakut |
348 |
333 |
354 |
297 |
253 |
271 |
344 |
234 |
136 |
334 |
231 |
100 |
521 |
Despite of mutual language influence of historical time, the model of genetic relationships of Turkic languages was built by using the calculated distances between languages according the formula:
L=Ko/(N + a),
where Ko – initial value of the proportional coefficient which is a little depended from the distance between languages therefore the constant a is introduced into the formula for correction. We took Ko = 3000 and a = 50 for the graphical model which is presented on the figure 6.
Built on these data, the scheme of the relationship of Turkic languages is shown below.
L=Ko/(N + a),
where Ko – initial value of the proportional coefficient which is a little depended from the distance between languages therefore the constant a is introduced into the formula for correction. We took Ko = 3000 and a = 50 for the graphical model which is presented on the figure 6.
Built on these data, the scheme of the relationship of Turkic languages is shown below.
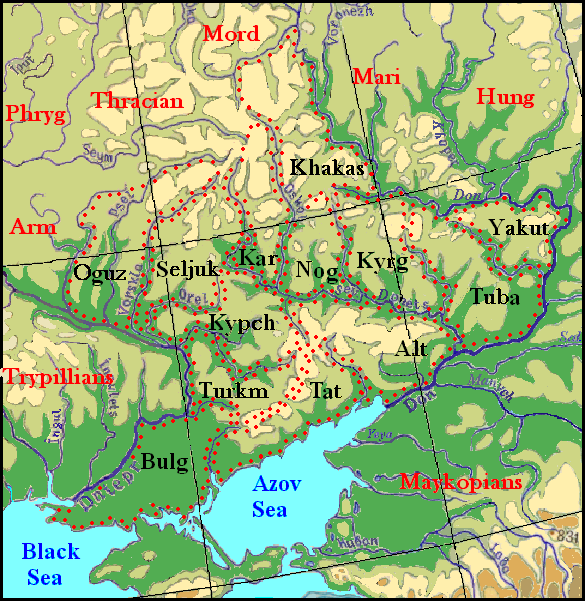
Searching for a place proper for this model, all attempts to locate it on the map near Altai region or in Siberia failed. The model can be put only on the region between the rivers Dnepr and Don where characteristic bend of the both rivers suggests us how to place the model (see map below). Thus, we have the reason to posit that Tutkic Urheimat was not in Altai but in Eastern Europe. Consequently the Proto-Turkic could not descend from a primaeval language called Altaic or Proto-Altaic as Sir Gerard Clauson expressed this though already fifteen years ago (CLAUSON GERARD, Sir, 2002, 36).
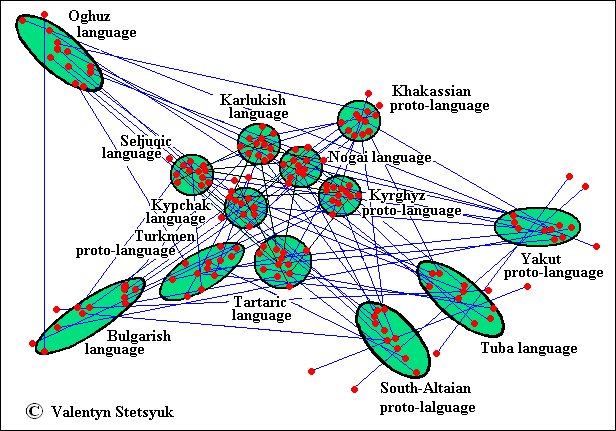
Above: The model of relationship of Turkic languages.
Right: The map of the Turkic habitats. Legend: Alt – Altaic, Arm – Armenish, Bulg – Bulgarish, Hung – Hungarian , Kar – Karlukish, Kypch – Kypchak, Kyrgh – Kyrghyz, Mord – Mordvinic, Nog – Nogai, Phryg – Phrygian, Tat – Tartaric, Turkm – Turkmen.
Right: The map of the Turkic habitats. Legend: Alt – Altaic, Arm – Armenish, Bulg – Bulgarish, Hung – Hungarian , Kar – Karlukish, Kypch – Kypchak, Kyrgh – Kyrghyz, Mord – Mordvinic, Nog – Nogai, Phryg – Phrygian, Tat – Tartaric, Turkm – Turkmen.
The Proto-Armenians resided on the left banks of the river Dniepr in the closest vicinity with Türks. Accordingly, the most words of the Türkic origin were found in the Armenian language. Some part of the Türkic words through the Armenian language even reached the ancient Greeks. The Türkisms in the Armenian, to which sometimes can be found matches in Greek, are given apart in the List of Traces of Linguistic Contakts between Indoeuropeans and Turks.
Not all Türkic loan-words survived in the Armenian language, and some part of them have not been found yet, that is why a small group of Türkic roots exist only in Greek. There is no doubt that matches to a part of them can be found in the Armenian language sometime. A separate deal of the Türkic-Greek lexical correspondences is represented by the Greek-Chuvash parallels which date from the more late time as the part of Greek ethnos stayed in Pontic steppes after the great deal of Ancient Greeks went for Balkan Peninsula. The Proto-Bulgars, the ancestors of Chuvash, had to stay on this territory for a long time too and adopted from the Greek some words, but the Armenian matches are not obligatory for them. The Greek-Chuvash lexical correspondences can be found in the same List of Traces of Linguistic Contakts between Indoeuropeans and Turks too.
Not all Türkic loan-words survived in the Armenian language, and some part of them have not been found yet, that is why a small group of Türkic roots exist only in Greek. There is no doubt that matches to a part of them can be found in the Armenian language sometime. A separate deal of the Türkic-Greek lexical correspondences is represented by the Greek-Chuvash parallels which date from the more late time as the part of Greek ethnos stayed in Pontic steppes after the great deal of Ancient Greeks went for Balkan Peninsula. The Proto-Bulgars, the ancestors of Chuvash, had to stay on this territory for a long time too and adopted from the Greek some words, but the Armenian matches are not obligatory for them. The Greek-Chuvash lexical correspondences can be found in the same List of Traces of Linguistic Contakts between Indoeuropeans and Turks too.
View Nostratic peoples in Eastern Europe in a larger map